From Web to RheumaLpack: Creating a Linguistic Corpus for Exploitation and Knowledge Discovery in Rheumatology
Alfredo Madrid-García, Beatriz Merino-Barbancho, Dalifer Freites-Núñez, Luis Rodríguez-Rodríguez, Ernestina Menasalvas-Ruíz, Alejandro Rodríguez-González, Anselmo Peñas.
Investigadores del grupo de Patología Musculoesquelética del Instituto de Investigación Sanitaria del Hospital Clínico San Carlos (IdISSC), la Universidad Politécnica de Madrid y la Universidad Nacional de Educación a Distancia han construido el primer recurso lingüístico, corpus (colección de textos representativa del uso de la lengua), de dominio específico de reumatología para la extracción de información, y para el entrenamiento de algoritmos de inteligencia artificial. Este corpus, bautizado como RheumaLpack, recopila y organiza de manera sistemática datos estructurados y no estructurados de diversas fuentes web, incluyendo registros de ensayos clínicos (ClinicalTrials.gov), bases de datos bibliográficas (Medline PubMed), agencias médicas (European Medicines Agency), redes sociales (Reddit), y sitios web de salud acreditados (MedlinePlus, Harvard Health Publishing y Cleveland Clinic).
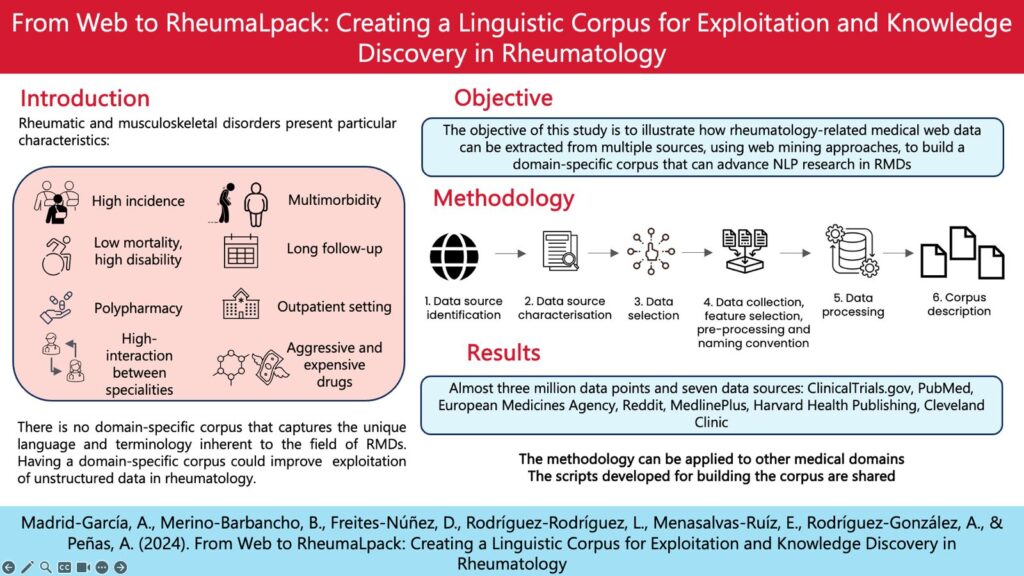
Para tal fin, los autores definieron una metodología en seis pasos: identificación de las fuentes de datos; caracterización de las fuentes de datos; selección de datos; recogida de datos, selección de características y preprocesamiento; procesado de los datos; y descripción del corpus. Esta metodología, que nació mediante la sinergia y el esfuerzo colaborativo entre ingenieros y reumatólogos, fue clave para la construcción del corpus.
RheumaLpack incluye información generada durante los años 2000-2023 de más de 9000 ensayos clínicos, 96000 abtracts, 2.5 millones de comentarios de medios sociales, así como información de más de 500 síntomas, tratamientos y test diagnósticos. La extracción de estos datos se hace mediante distintas técnicas de minería web, como llamadas REST-API y raspado web (web scrapping).
Para demostrar la aplicabilidad de RheumaLpack, los investigadores presentan un caso de uso que, empleando los últimos avances en procesamiento de lenguaje natural, muestra los temas y las inquietudes de pacientes que sufren síndrome de Sjögren en uno de los mayores foros a nivel mundial, Reddit.
Finalmente, la metodología propuesta por los investigadores es replicable a otras enfermedades, y el código utilizado para generar dicho recurso lingüístico es público, facilitando la reproducibilidad de los resultados y pudiendo ser usado en otros ámbitos y disciplinas de la medicina. Los resultados junto con el código de esta investigación han sido publicados en la revista Computers in Biology and Medicine.





